セキュリティ
AIモデルの安全性を客観的に把握可能
F5ネットワークスジャパンは4月23日、脅威インテリジェンス・リソース「F5 Labs AI Security Leaderboards」を発表した。これは、主要なAIモデルのリスク評価をスコア化し、月次で公開するサービスだ。
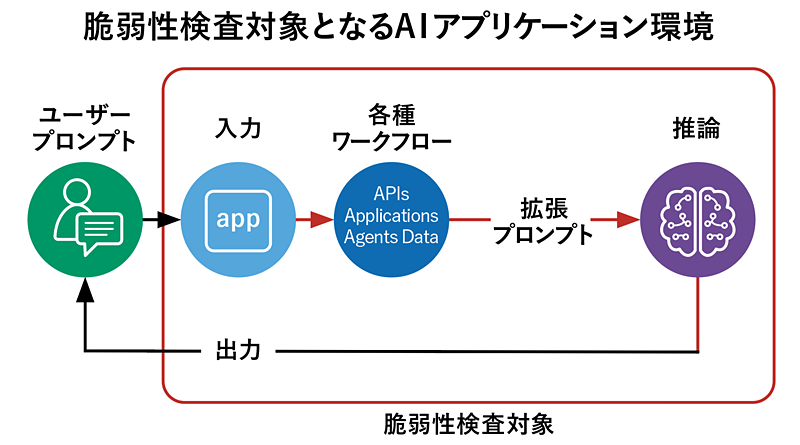
開発の背景には、LLM(大規模言語モデル)が抱える三つの脆弱性が挙げられる。一つ目はLLMには権限や信頼できる情報源の概念が内在しないこと、二つ目は直近または文脈的に強い指示に従いやすいこと、三つ目は間接型プロンプト・インジェクションがシステムプロンプトを迂回することだ。これらの脆弱性に対して、AIモデルの安全性を客観的に評価する指標となるのが、F5 Labs AI Security Leaderboardsである。
本サービスは、「Comprehensive AI Security Index」(CASI)と「Agentic Resistance Score」(ARS)の二つの指標で構成されている。いずれも同社が毎月収集している1万件以上の攻撃プロンプトに基づき、実際にAIモデルへ攻撃を仕掛けるというものだ。CASIは、一般的なプロンプト・インジェクション攻撃やジェイルブレイク攻撃に対する脆弱性を測定する。これに対して、ARSは実運用に近いマルチステップかつ自律的なエージェント環境において、モデルがどれだけ耐性を保てるかを測定する。検査対象が異なる二つの指標により、単一のプロンプト内で発生する単発攻撃と、複数の会話ステップにわたって進行する多段攻撃の両方に対する耐性を測れるのだ。
同社 CTO 丸瀬明彦氏は「モデルの正確な強度を測るためには、攻撃の内容や特性に応じて、セキュリティ強度を判定する必要があります」と評価基準の考え方を語る。例えばCASIのスコアには、攻撃の深刻度や複雑さ、最短で攻撃が成立するパス・コストが反映されている。こうした特長により、安全性の基準を満たすAIモデルの絞り込みや、ビジネスのインテントに合わせたガードレールの設定などに活用される見通しだ。