

データはある、しかし「使えない」
AI活用が突きつける「使える化」
企業のデータ活用が新たな局面を迎えている。DXの推進とともに、生成AIの普及が加速する中で、企業内のデータ整備とガバナンスの重要性が改めて問われている。生成AI時代の到来は、企業にとって「データの再定義」を迫る転機である。今こそデータ活用基盤の整備に本腰を入れるべき時だ。
企業におけるデータ活用基盤の実態
「守り」は強いが「攻め」に弱い

川勝健司 氏
ビジネスでの生成AIの活用事例が次々と公開されている。そうした中でこれまで生成AIの活用に積極的ではなかった企業も、その可能性に注目し始めている。
しかしAI活用を進めるに当たり、企業が見落としてはならない重要な要件がある。それは「データ活用基盤」の整備だ。EYストラテジー・アンド・コンサルティング(以下、EY)のリスク・コンサルティング パートナー 川勝健司氏は「AIを活用するには、まずデータの整備と品質の向上が不可欠です。生成AIは画像や音声、テキストといった非構造化データも扱えるようになりました。だからこそ、データの管理とガバナンスがより重要になってきています」と指摘する。
EYは2021年に実施した「データガバナンスサーベイ 2021」の調査結果の一部を公開している。この調査は日本企業のデータガバナンスの整備・運用状況の成熟度を明らかにするもので、国内企業506社を対象に実施された。公開されているデータは少し古いものとなるが、データガバナンスに関わるコンサルティングの現場で感じる問題の本質は現在も変わらないという。
なおEYはデータガバナンスについて「広範な領域に跨るデータ資産の管理におけるルールと順守基準を策定して統制すること」と定義している。
調査の結果、「知識領域別成熟度」については、データの保護や情報漏えいなどを防ぐことが主眼に置かれた「データセキュリティ」や「データストレージとオペレーション」という、「守り」の対策では比較的高い成熟度であった。
一方でデータ利活用のための基盤となる「データガバナンス」や「データアーキテクチャ」「メタデータ管理」などの平均成熟度は低い結果だった。
これは収益を増加させる目的やESGなどのサステナビリティ関連の活動状況を非財務情報として開示する目的など、いわゆる「攻め」のデータ利活用で重要となる領域であり、複数の異なる情報源からデータを入手して加工・変換など行った上で蓄積・利用することが求められ、組織横断的にデータを利活用するための環境と体制の整備がされているかを意味する。残念ながら日本企業ではそれが不十分な状況であるというわけだ。
AIエージェントを育てるには
質の高い学習データが不可欠

藤生尊史 氏
特に顕著なのが部署や事業ごとにデータが分散し、全社的な活用が困難な「サイロ化」の問題だ。川勝氏は「例えばある運輸業では営業部門、運行管理部門、整備部門などがそれぞれデータを保有していますが、横断的な活用はあまり行われていません。結果として顧客の細かな需要や車両の整備状況を運行計画に反映するなどの連携ができず、データ活用の効果を享受できているとは言えない状況です」と説明する。このような状況は業種を問わず多くの企業に共通する課題だ。
さらに非構造化データの増加により、従来のデータ管理手法では対応しきれないケースも増えているという。生成AIの登場は企業のデータ活用に新たな視点をもたらした。従来は構造化データを中心に活用していた企業も、今や画像、音声、テキストなど多様な非構造化データを扱う必要がある。
川勝氏は「AIエージェントを業務に適用させるためには、質の高い学習データが不可欠です。企業内にあるデータをAIが使える形で整備することが求められています」と指摘する。単にデータを蓄積するだけでなく、ラベリングやメタデータの付与、アクセス権限の管理など、データの「使える化」が必要だ。加えてデータのライフサイクル全体を見据えたガバナンス(生成から廃棄までの管理体制)も不可欠となる。
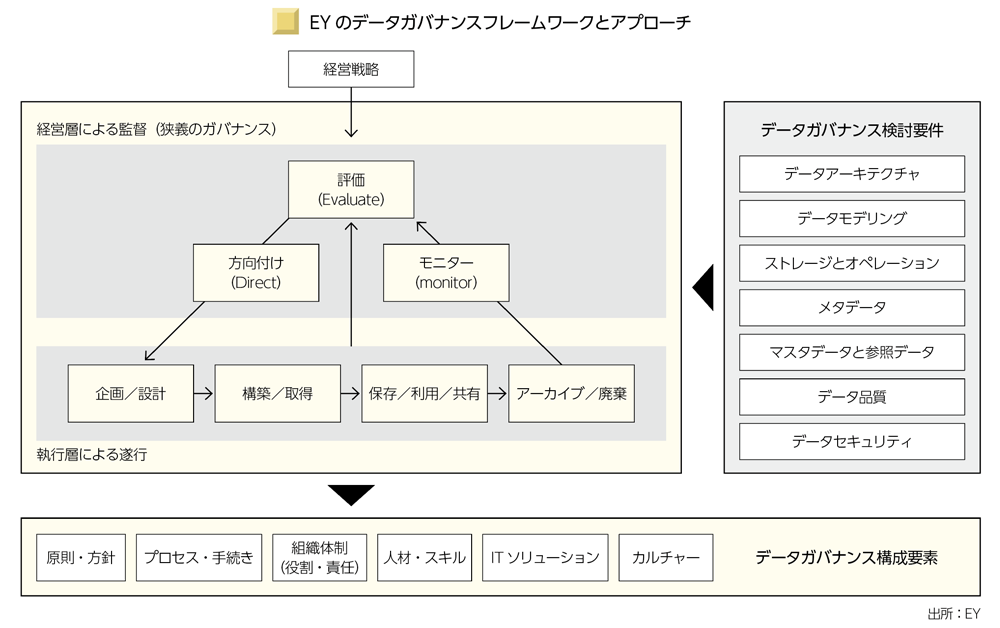
EYではデータガバナンスを「経営層による監督」と「執行層による遂行」の2層で構成しており、四つのステップで構築を支援している(別掲図を参照)。
従来のデータガバナンスは中央集権型が主流だった。財務データなどを一元管理し、経営判断に活用するというモデルである。しかし事業部ごとの独立性が高い企業では、このモデルが限界を迎えている。
同社のリスク・コンサルティング シニアマネージャー 藤生尊史氏は「最近では分散型のガバナンスに注目が集まっています。各事業部にデータ管理の権限を持たせつつ、全社的なポリシーやルールで最低限の統制を図る、いわば"地方自治型"のガバナンスです」と説明する。
このモデルでは各部門が自らの業務に必要なデータを管理・活用し、品質を担保した上で他部門と共有する。結果としてデータの流通と活用が促進され、全社的な最適化が可能になる。
データは第四の経営資源
顧客や社会に対する責任も
では企業はどのようにしてAI活用に向けたデータ活用基盤を構築すべきなのか。次に示すロードマップの通り、企業は目的に基づいて段階的にデータ活用基盤を整備していくことが求められる。
1. 目的の明確化
AI活用の目的を定義し、どの業務領域でどのような価値を創出したいのかを整理する。
2. ユースケースの選定
目的に沿った具体的なユースケースを選び、必要なデータと機能を洗い出す。
3. 既存資産の活用と評価
データウェアハウスやBIツールを導入済みならば、それらを改めて評価し、活用可能な部分と刷新すべき部分を見極める。
4. ガバナンス体制の整備
CDO(Chief Data Officer:最高データ責任者)を中心としたガバナンス体制を構築し、事業部門との連携を強化する。
5. プラットフォームの構築
拡張性と柔軟性を備えたデータプラットフォームを構築し、非構造化データも含めた統合管理を実現する。
データ活用基盤の整備は単なるIT投資ではない。企業の競争力を左右する戦略的な取り組みである。生成AIの活用が進む中、社内に蓄積されたデータをいかに価値ある情報へと昇華させるか、その力が企業の未来を決定づける。
川勝氏は「データがヒト・モノ・カネに次ぐ第四の経営資源と言われて久しいですが、生成AIやAIエージェントの登場によって、データを生かせる企業とそうでない企業との差は指数関数的に開いていくでしょう」と強く語る。
AIエージェントが企業間でデータをやりとりする未来を見据え、今からデータの整備と管理体制の構築を進めることが、持続可能な成長への鍵となるだろう。
AI時代を生き抜くために欠かせない
データ活用基盤とDWHの構築・再構築
生成AIの登場によって、企業における生成AI活用に対する意識が急速に高まっている。しかし、いざ活用を始めようと一歩踏み出した際に「社内データが活用できる状態になっていない」という壁に直面する企業は少なくない。こうした壁を乗り越えるためには、現在企業で構築しているデータ活用基盤やDWHの見直しを図る必要がある。では、どのようにデータ活用基盤やDWHの構築・再構築を行っていけば良いのか、取り組み方法や留意点などを探っていく。
データ基盤の見直しで
AI時代のデータ活用に対応

松本尚樹 氏
業種や業界を問わず、多くの企業でAIを活用しようとする動きが加速している。それに伴って、AIの活用に必須となるデータに関する課題に悩まされる企業は少なくない。「企業が直面する課題の一つにデータの整備不足が挙げられます。データ自体が社内に散在しており、利用できる形に整っていないというケースです。生成AIのパフォーマンスは、提供されるデータの質に大きく依存します。蓄積されたデータを適切に整備することで、AIの性能を最大限に引き出せますが、データが活用できる状態でなければ、AIの導入さえままなりません」とEYストラテジー・アンド・コンサルティング テクノロジーコンサルティング パートナー 松本尚樹氏は話す。
データの活用やデータ基盤の整備は、DX(デジタルトランスフォーメーション)やデータドリブン経営などの推進と共に、見直しが進められてきたが、依然としてさまざまな問題が企業に残されているという。「大企業では、データを活用できる環境を構築していたとしても、特定の部署やデータを絞ったAI活用やデータドリブン経営にとどまっているケースがほとんどです。特定の部署で先進的な取り組みが進んでいても、全社横断でのデータ活用となると、そこまで到達している企業は少数であるとみています。一方、中堅企業では、部署ごとの取り組みでさえ始められていなかったり、そもそも着手できていなかったりするケースもあります。こうしたデータの活用やデータ活用基盤の整備に関する取り組みが遅れていることは、早急に対処すべき課題であるといえるでしょう」と松本氏は話す。
企業で扱うデータの種類は、数値データ、テキストデータ、画像データ、音声データなど多岐にわたる。こうしたデータに関しても、細部までは生かしきれていないケースが多いという。「部門ごとにデータを集計し、1カ月単位などのタイムラインで過去のデータを追って活用するといった業務に生かす取り組み自体は進みつつあります。しかし、データの粒度や解像度が低いため、業務の詳細な情報までは網羅できず、人が介在してデータを確認するなどの作業が発生しています。この問題を解消するためには、データの粒度を細かくし、データを活用できる体制を整えなければなりません」(松本氏)
こうしたことからデータの活用が進んでいる企業であっても、今後はデータの粒度を高めて、より詳細なデータを活用できる環境を整えていく必要がある。データの活用が盛んに行われるAI時代の今、改めてデータ基盤の構築や見直し、データ収集の仕組みの自動化、適正化を進める絶好のタイミングであるといえるだろう。
スモールスタートが成功の鍵
小さなアプローチが重要
データ活用基盤やDWH(データウェアハウス)をすでに構築している企業にとって、既存のデータ基盤を「拡張」するのか、それとも全面的に「再構築」するのかという根本的な判断が求められる。企業はどちらの選択をすべきなのか、松本氏はこう説明する。「既存のシステムが比較的柔軟で、特定のシステムと密に結合していない場合は、データの取得方法やバリエーションを見直すことで既存のまま対応できます。しかし、既存のシステムが特定の業務や技術に密結合している場合は、拡張が困難なケースが多いでしょう。その場合は、クラウドシフトのような形で、新しく別のデータ基盤を構築し、そこからデータを連携させたり、切り離したりできるように刷新していくというアプローチが有効です。拡張するか、再構築するか、企業によって最適解は異なりますが、昨今の傾向では既存のシステムに固執することなく、再構築を図る企業が増えていると感じています」
新しい基盤を構築する際の重要な視点は、将来的な変化に対応できる柔軟性だ。これまでのDWHが表形式のデータを中心としていたのに対し、AI時代には動画、音声、さらには人間の表情といった非構造化データも活用対象になる。扱うデータの種類と量は今まで以上に爆発的に増加するため、再構築に当たっては、将来的にデータの種類や量が変化することを前提としたシステムアーキテクチャやDWHを設計していくことが重要だ。
これまでDWHなどを構築してこなかった企業が、新たにこうしたシステムを導入するといったケースもあるだろう。そうした場合には、どのような点に注意するべきだろうか。「データ活用基盤の構築は、企業の存続が続く限り永遠に更新していくべき、終わりなき取り組みです。だからこそ、最初から全社横断で壮大なゴールを目指すのではなく、小さく始める『スモールスタート』が成功の第一歩となります」(松本氏)
全社横断でやろうとすると、部門間の調整だけで1年かかってしまうといったケースも珍しくない。結果が出ないまま頓挫してしまう企業は非常に多いという。まずは少量でも良いので早く効果を出し、その成功を実感することで「これは良いものだ」という実感を組織全体に浸透させていく。こうした小さなアプローチが何よりも重要になる。
また、体制の構築についても注意が必要だ。システム部門と営業などの業務部門、いずれか一方だけで進めるのではなく、必ずシステム部門と業務部門が混成したチーム体制をつくることが重要であるという。互いの視点がずれてしまうことを防ぎ、スムーズな連携を可能にするためだ。さらに、特に中堅企業では、トップ層の旗振り役が不可欠となる。「トップダウンで旗印を立て、会社全体を先導していくことが望ましいです。通常の業務がある中で、新たな取り組みを進めることは現場に負荷をかけます。なぜこの取り組みが必要なのか、その意義をトップが明確に示すことで、従業員の協力を得やすくなります」(松本氏)
データ活用はマストの取り組みに
時代変化に対応できる基盤構築が重要
スモールスタートで始める場合でも、全社的にどのようなデータがあり、どのような課題があるかを把握するための「As-Is(アズイズ)調査」は欠かせない。しかし、現状を把握するための「調査」、収集した情報の「整理」、改善策を実行する「アウトプット」と順序通りに進めると、成果が出るまでに時間がかかってしまう。そのため、調査とアウトプットを並行して進め、1カ月から3カ月程度の短期間でダッシュボードを一つ作ってみるなど、スピード感を持って具体的な成果を出すことがポイントになるという。
データ活用基盤の構築に当たって、従来は「完璧な状態」を目指して、最初に計画を固めるウォーターフォール型のアプローチを取る企業が多かった。しかし、そうした場合にうまくいかず、計画通りに進まないこともある。「ウォーターフォール型で『完璧なもの』を作ろうとすると、多くのケースで失敗します。例えるなら、最初から完璧な家を設計しようとしても、具体的なイメージがないため、途中で『煙突なんていらなかった』といったように当初計画していたものからずれてしまうことがあります。スモールスタートで小さなものをまず作成して、それを見ながら軌道修正していくアプローチでないと、やりたいことと最終的な成果にギャップが生まれてしまい、良い取り組みになりません。結果的に無駄なコストもかかってしまいます」と松本氏は説明する。
今後のAIの進化を考えると、社外とのデータ連携は不可避となる。その際、自社のデータが使い物にならない状況では、市場から取り残され、競争優位性低下の可能性もあるという。データ活用はもはや先進的な取り組みではなく、取り残されないためのマストな取り組みとなっている。「特にBtoCビジネスでは、適切なレコメンデーションを行うために、膨大なデータを扱い、AIを使い倒していくことが不可欠になります。競合他社がデータやAIの活用を推進する中で、これまでと同じやり方では、新たな価値創出や顧客から自社を選んでいただくことはより難しくなるため、新たな武器であるAIをより活用していくためにも、データ活用基盤の見直しは重要です」(松本氏)
データ活用基盤の構築は、単なるシステム導入ではない。それは、企業の未来を左右する経営戦略そのものだ。目の前の課題解決から小さくスタートし、現場の共感を得ながら、時代の変化に対応できる基盤を構築していくことが、これからの企業には求められるだろう。

ストレージの役割は“保存”から“活用”へ
生成AI時代に選ばれるオンプレミスLLM基盤
さまざまなストレージをラインアップする日本ヒューレット・パッカード(以下、HPE)。その同社がAI向けストレージとして現在主軸としているのが「HPE Alletra Storage MP X10000」だ。生成AI時代だからこそ求められるオンプレミス環境のLLMモデルを運用するデータ基盤として最適な本製品の特長と、活用によって得られる効果について、HPEに話を聞いた。
LLMの限界を補うRAGと
データ変換のハードル

山中伸吾 氏
「当社が提供する『HPE Alletra Storage MP X10000』(以下、MP X10000)は、RAG(Retrieval-Augmented Generation:検索拡張)を用いたオンプレLLM(大規模言語モデル)の運用に最適なオブジェクトストレージです。ストレージという名称を付けてはいますが、本製品の中身自体はサーバーです。いわゆるソフトウェア・ディファインド・ストレージ(SDS)ですので、さまざまなソフトウェアを入れ替えて多様な運用を行うことが可能な製品で、ストレージという領域を越境し、AI活用に特化した機能を提供できる製品です」と力強く語るのは、HPE パートナー・アライアンス 営業統括本部 ストレージ営業部 部長 山中伸吾氏。
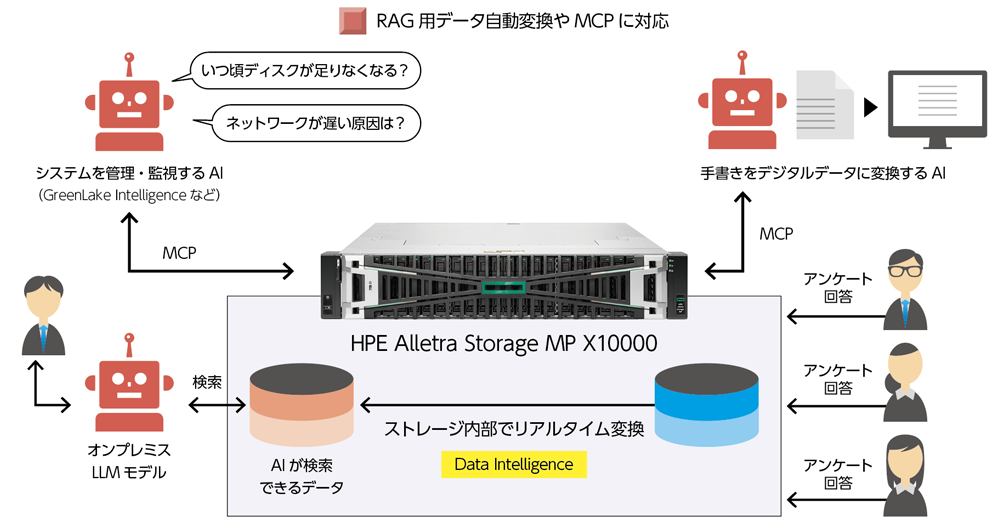
例えば、生成AIの一種であるLLMは、大量のデータを学習することで回答のテキスト生成を可能にしているが、その回答内容は学習した時点より過去の情報に基づく。つまり1年前に学習したLLMを使っている場合、昨日の情報を尋ねても正しい情報が回答されない。もちろんファインチューニング(微調整)によってこの学習済LLMモデルの情報を更新することは可能だが、コストと時間がかかるため頻繁な再学習は現実的ではない。そこで注目されているのがRAGだ。社内のデータを参照し、学習していない情報からでも回答が可能になる。しかし一方で、社内のデータをAIが検索するには、AIが認識できるデータに変換する「データパイプライン」の実行が求められる。
山中氏は「一口にデータの変換といっても、それを行うには時間も人手もかかりますので毎日対応するのは現実的ではありません。しかし、リアルタイムに処理しなければ昨日のアンケート結果などの情報をLLMに聞いても回答できない、という事態になってしまいます。そうしたデータ変換の負担を削減するため、MP X10000では『Data Intelligence』という機能を新たに提供しています」と語る。
Data Intelligenceが実現する
リアルタイムデータ活用
Data Intelligenceは、前述したデータ変換を、ストレージ内部でリアルタイムに自動変換してくれる機能だ。これによって社内で使っているLLMが、いつでも最新のデータを参照しながら精度の高い回答を行えるようになるのだ。「これにより、人力の対応では難しかったリアルタイムでのデータ反映が可能になります。例えば1時間前のデータでも参照が可能になるのです。全自動でここまで対応できる製品は、競合他社を見ても珍しいと思います」と山中氏は笑う。
このData Intelligenceについて、HPE データサービス事業統括本部 データサービス技術部 冨澤 渉氏は次のように説明する。「Data Intelligenceは端的に言えば、データパイプラインを作る機能です。RAG用データ作成の自動化を例に流れを紹介しますと、Data Intelligenceではデータを内部のバケットに保存すると、『Apache Kafka』を経由してData Intelligence Serverにデータを引っ張ってきます。ここでデータパイプラインでRAG用のデータにリアルタイムにベクトル化し、ベクターデータベースに保存します。それらのベクトルデータ&インデックスデータをLLMと連携することで、リアルタイムにデータが反映されたRAGを利用した回答生成が可能になります」
なおこのAI分析用のデータはLLMを利用する一般ユーザー(従業員)が閲覧できないよう分離されている。
「このData Intelligenceを活用することで、データは保存するだけでパイプラインを通して自動でRAG用のデータに変換され、RAGですぐに利用できるようになるため、最新のデータを活用し、データ分析の運用負担が大きく削減可能です。データパイプラインと一口に言っても、精度の高い回答を得るためには、正確なデータを更新し続ける必要があります。それには正しい知識と情報をもった専門家とデータエンジニアが連携し適切にデータマネジメントする必要がありますが、それが大変なことは皆さまも周知の事実かと思います。しかしMP X10000のData Intelligenceを使えば、決まった場所に専門家がデータを保存するだけで、後は自動でRAG用のデータに変換されるため、AIによるデータ活用基盤の運用負担が大きく削減できるでしょう」と冨澤氏は活用メリットを話す。
MCP対応で広がる
AI連携と運用自動化

冨澤 渉 氏
MP X10000を活用することでAI同士が連携した運用も可能になる。2025年6月23〜26日に米国ラスベガスで開催された「HPE Discover Las Vegas 2025」において、MP X10000はMCP(Model Context Protocol)をサポートすることを発表した。これによって手書きデータをデジタルデータに変換するAI-OCRや、システムを管理・監視するAIなどとシームレスに連携できるようになる。山中氏は「例えば手書きのアンケート結果をテキスト化するAI-OCRと連携し、そのデジタルテキストデータをMP X10000に保存できますし、システム管理AIと連携すれば運用管理の負担も低減可能です。当社で提供しているAIエージェント型運用自動化フレームワーク『GreenLake Intelligence』もこのMCPに対応していますので、例えば『いつ頃ディスクが不足する?』『ネットワークが遅くなった原因は何?』といったMP X10000運用時のトラブルを自然言語で確認できるのです」と語る。MP X10000はデータ増加に応じて段階的に容量の拡張も行えるため、AIデータ基盤として運用する場合に増大していくデータ分析にも対応がしやすい。
冨澤氏は「過去、ストレージはデータの保管場所でしたが、AIの台頭によってこれからのストレージはデータを活かす場所になるでしょう。これまでただの倉庫であった場所が、市場のような存在になっていくようなイメージです。MP X10000はMCPに対応したData intelligenceによってデータの活用を促進し、よりビジネスを加速させていくことが一つのビジョンです」と語る。
HPEでは現在、AIデータ保管からデータ活用までをカバーするプライベートAIクラウド「HPE Private Cloud AI」をパッケージとして提供しているが、今後このパッケージの中にMP X10000も含まれる予定だ。AI開発から活用までをトータルにサポートするHPEは、今後AI活用事例の創出を含めてさまざまな側面から企業のサポートを続けていく。