NTT、大規模言語モデルの新バージョンを発表
事業戦略
NTTは10月20日、大規模言語モデル(LLM)「tsuzumi」の新バージョンとして「tsuzumi 2」を発表した。tsuzumi 2には、主に三つの特長がある。
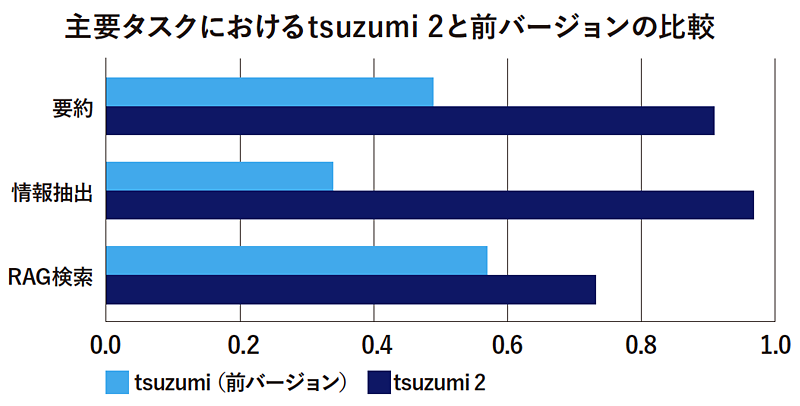
一つ目は性能の向上だ。同サイズ帯モデルの中で世界トップクラスの日本語性能を実現し、「gpt︱oss︱120B」「GPT︱5」といった数倍以上の大規模モデルにも匹敵する精度を誇る。さらに、RAG検索やドキュメントからの情報抽出・要約のタスクといった、ビジネスシーンで頻繁に利用される機能を重点的に強化している。
二つ目は特化型モデル開発効率の向上だ。金融、医療、自治体といった顧客から要望の多い業界を中心に、専門知識の学習強化を行っている。これにより、少ないデータでのチューニングが可能となり、迅速かつ低コストで高精度なカスタマイズを実現できる。例えば金融分野では、ファイナンシャルプランニング技能試験2級の合格基準に到達するために、他モデルが1,900問の追加学習を必要とするのに対し、tsuzumi 2はわずか200問で済むのだ。他モデルと比較して、追加学習データ量を10分の1に抑えている。
三つ目は、低コスト・高セキュア・国産AIという従来の強みを維持している点だ。パラメーターサイズは約300億と1GPUに収まる設計になっているため、オンプレミス環境での導入が容易で、低コスト運用が可能だ。さらにオンプレミス導入により、入力データが外部に漏えいしない高いセキュリティも確保できる。また、tsuzumi 2はNTTがゼロからフルスクラッチで開発した純国産のLLMであるため、学習データのコントロールを実現している。これにより、データの権利、品質、バイアスといった管理が可能となり、モデルの信頼性が一層高まっているのだ。
NTT 代表取締役社長 島田 明氏は「tsuzumi 2の提供によって、新たな価値を創造し、お客さま体験の高度化に向けた取り組みをさらに加速していきます」と今後の意気込みを語った。