

二つの技術をコアとした生成AI再構成技術が
大規模言語モデルの軽量化と省電力を実現
富士通は9月8日、同社のAIプラットフォームである「Fujitsu Kozuchi」のコア技術として「生成AI再構成技術」を開発し、富士通のLLM「Takane」の強化に成功したことを発表した。本技術は、二つのコア技術を基にして、大規模言語モデル(LLM)の軽量化と省電力を実現している。記事では、生成AI再構成技術の開発の背景と二つのコア技術である「量子化技術」「特化型AI蒸留技術」の概要、そして富士通が考える本技術の今後の展望について紹介する。
生成AIの進化が生む
計算資源と消費電力の課題

富士通研究所
人工知能研究所
生成AIコアプロジェクト
シニアプロジェクトディレクター
白幡晃一氏
富士通が9月8日に発表した、大規模言語モデル(LLM)の軽量化・省電力を実現するAI軽量化技術「生成AI再構成技術」の開発背景について、同社 富士通研究所 人工知能研究所 生成AIコアプロジェクト シニアプロジェクトディレクター 白幡晃一氏はこう語る。「近年、生成AIの進化に伴い、計算資源や消費電力の増大が深刻な課題となっています。実際、2010年から2022年の12年間で、AIの計算能力は10の10乗倍にまで拡大しました。処理性能が飛躍的に向上する一方で、それに比例して必要な計算資源や消費電力も増加の一途をたどっています。こうした状況を踏まえると、計算資源と消費電力の効率化は、AIエージェントの社会実装・普及に向けた重要な課題であると言えます」
このような課題認識の下、富士通は自社のAIプラットフォーム「Fujitsu Kozuchi」と、LLM「Takene」の研究開発を進めている。Takeneは企業利用を前提として設計されているため、計算資源と消費電力の効率化がより一層求められる。こうした要請に応えるべく、Takeneでは企業ごとに最適な設計にファインチューニング可能な構造を採用しており、精度の向上とともに計算資源および消費電力の効率化を実現している。
さらに富士通は、Takeneを基盤として企業内での生成AI活用を最大限に推進するため、2024年6月に「エンタープライズ生成AIフレームワーク」を発表した。このフレームワークは、生成AIモデルの再構成などを通じて最適なモデル構築を行う「顧客環境への適応力」、データの構造化などを担う「企業データ理解」、そしてハルシネーションの抑制やLLMの脆弱性対応、ガードレール対応などを含む「高い信頼性」という三つの軸で構成されている。これら三つの軸を推進することで、将来的にAIエージェントと共に実現を目指す世界を支える基盤とする。今回発表された生成AI再構成技術は、顧客環境への適応力に位置付けられる。
データ量を圧縮し電力を抑える技術と
専門知識を凝縮し精度を向上させる技術
それでは生成AI再構成技術の二つのコア技術を見ていこう。一つ目が「量子化技術」だ。量子化とは、AIモデルの中でニューロン同士のつながりに使われる重みのデータ量を圧縮する技術を指す。通常、重みは32ビットや16ビットで表現されるが、量子化によってこれを1ビットまで削減することが可能になる。この圧縮によってモデル全体のサイズが小さくなり、メモリーがデータを読み書きする際の負荷が軽減される。その結果、消費電力の削減や処理時間の短縮といった効果が得られるのだ。しかし、LLMのように多層構造を持つ大規模なニューラルネットワークでは、量子化によって生じる誤差が層を重ねるごとに蓄積され、結果としてモデルの精度が低下するという課題があった。
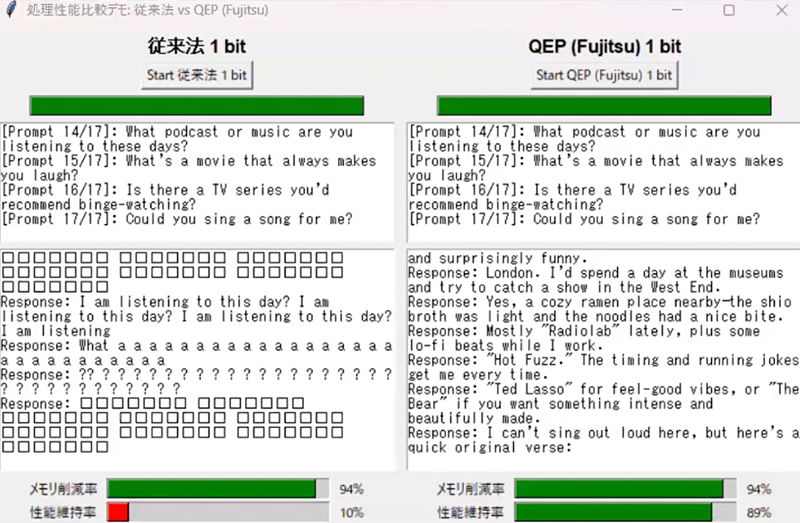
こうした課題を解決するために富士通では、量子化による誤差を軽減する技術「Quantization Error Propagation」(QEP)を独自開発した。従来の手法では、各層で量子化を行うだけで誤差への対応は限定的だったが、QEPでは層ごとに誤差を補正する仕組みを導入している。これにより、量子化によって発生する誤差を最小限に抑えることが可能となった。さらに、富士通が開発した組合せ最適化問題向けのアルゴリズム「Quasi-Quantum Annealing」(QQA)活用することで、量子化に伴う誤差を一層削減している。「従来の手法では精度維持率が20%を下回っていました。しかしQEPとQQAを活用することで、精度維持率を89%まで向上できます。高い精度を保ちながら、処理速度は従来比で3倍の高速化を実現しています。これにより、ハイエンドのGPU4枚を必要とする大型の生成AIモデルを、ローエンドのGPU1枚で高速に実行することが可能となりました」と、白幡氏は強調する。
二つ目のコア技術が「特化型AI蒸留技術」だ。もともとLLMの軽量化手法としては、大規模なモデルからより小さなモデルへ知識を移す「蒸留」という技術が知られている。特化型AI蒸留技術はこの蒸留手法をベースに、特定のユースケースに必要な知識だけを抽出・移行したり、新たな知識を追加したりすることで、目的に応じた特化型AIモデルとして再構築する技術だ。
まず、基盤となるAIモデルに対して、不要な知識を削ぎ落とす「Pruning(枝刈り)」や、新たな能力を付与する「Transformerブロックの追加」などを行い、多様な構造を持つモデル候補群を生成する。次に、富士通独自の代理評価技術を活用した「Neural Architecture Search」によって、GPUリソースや処理速度、精度といった顧客の要件に応じた最適なモデルを自動で選定する。そして最後に、選定された構造を持つモデルに対して、Takaneなどの教師モデルから知識を蒸留することで、特化型AIモデルが完成する。
この特化型AI蒸留技術によって作成されたモデルは、推論速度を従来比で11倍に高速化しながら、精度を43%改善することに成功している。さらに、教師モデルを上回る精度を、パラメータサイズが100分の1という軽量なモデルで達成できることも確認されており、必要なGPUメモリーと運用コストをそれぞれ70%削減しながら、高い信頼性を持つ予測を可能にしている。また、画像認識タスクにおいては、未学習の物体に対する検出精度を既存の蒸留技術と比較して10%向上させるなど、応用面でも高い成果を上げている。

業種特化型のTakeneの開発など
Takaneの進化を加速させていく
最後に白幡氏は今後の展望について、以下のように語った。「本技術を適用することでTakaneの進化を加速させ、お客さまのビジネス変革を支援するとともに、今後は金融、製造、医療、小売など、より専門性の高い業務に特化したTakaneを順次開発・提供していきます。また当社は、本技術をさらに発展させ、生成AIの精度を維持したままモデルのメモリー消費量を最大1,000分の1へ削減し、あらゆる場所で高精度かつ高速な生成AIが利用できる世界の実現に貢献していきます。さらに将来的には、これらの特化型Takaneを進化させて、世界の仕組みや因果関係をより深く理解し、複雑な課題に対して自律的に最適な解決策を導き出すAIエージェント向けの生成AIアーキテクチャに発展させていきます」
また富士通は量子化技術を適用したTakaneのトライアル環境を2025年度下期より順次提供を開始する。また技術の普及と検証を促すため、Cohereの研究用オープンウェイト「Command A」を本技術により量子化したモデルを「Hugging Face」を通じて9月8日より順次公開している。
